

Introduction
ChatGPT [1], or the underlying Large Language Models (LLMs) today, are able to generate contextualized text/image responses given a prompt. Prompt Engineering refers to adapting the user query, providing the right enterprise context and guidance to the NLU and NLG engines — to maximize the chances of getting the ‘right’ response. The prompts can be relatively long, so it is possible to embed some enterprise context as part of the prompt.
As a next step in the Gen AI evolution, we expect the text/image responses to be more and more personalized, e.g., with respect to the current sentiment and past preferences of the user.
Technically, this implies adding a Personalization module / Recommendation Engine [2] to Large Language Models (LLMs) to provide a highly interactive and personalized experience. (Reinforcement Learning, in the form of RLHF, is already leveraged during LLM training to improve the quality of its responses.)
In this article, we propose a Reinforcement Learning enabled solution architecture to personalize the LLM generated responses.
LLM Basics
Broadly, a Chatbot based on LLMs (note that the new GPT models are multi-modal), follows the below steps:
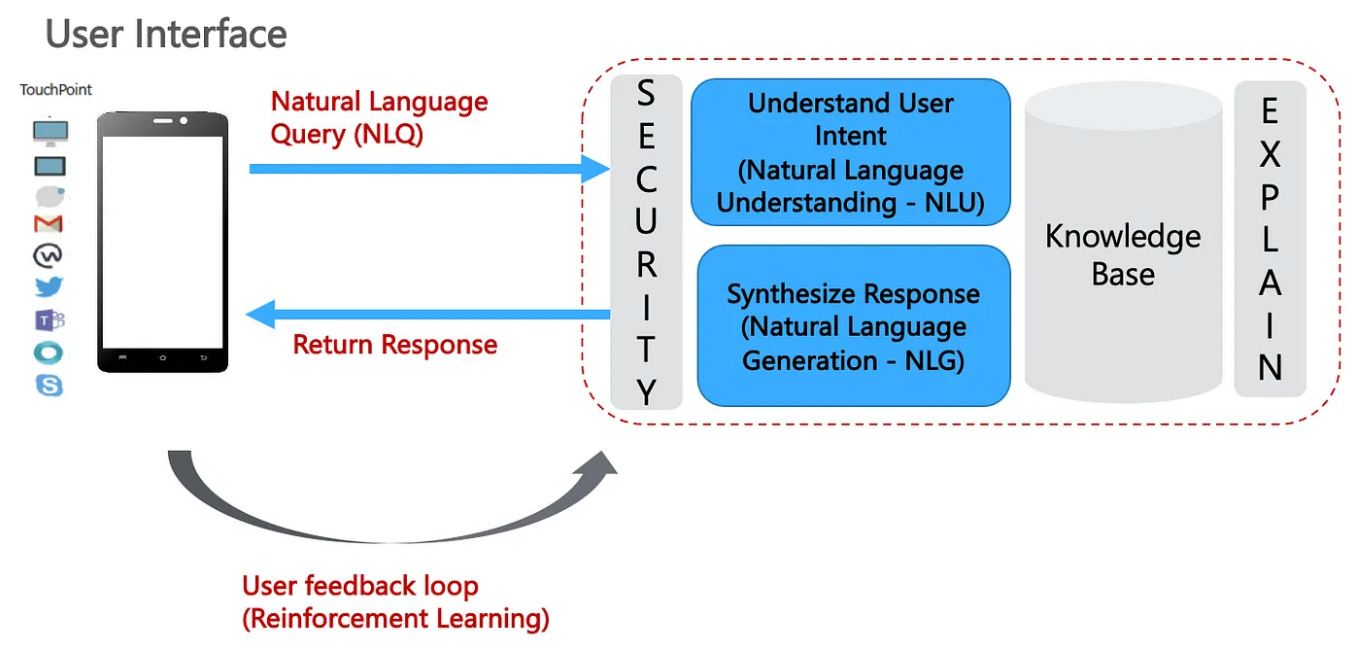
Natural Language Understanding (NLU): Given a user query, first understand the user’s intent;
Retrieve the relevant content from its underlying Knowledge Base (KB), be it in the form of embeddings or Knowledge graphs. Refer to [3] for a list of applicable Gen AI — LLMOps architecture patterns.
Natural Language Generation (NLG): Synthesize the answer and respond to the user;
The user feedback loop is important here and LLMs, including ChatGPT, make extensive use of RLHF to improve their accuracy.
Reinforcement Learning from Human Feedback (RLHF)
Reinforcement Learning (RL) [4] is a powerful technique that is able to achieve complex goals by maximizing a reward function in real-time. The reward function works similar to incentivizing a child with candy and spankings, such that the algorithm is penalized when it takes a wrong decision and rewarded when it takes a right one — this is reinforcement.

At the core of this approach is a score model [5], which is trained to score chatbot query-response tuples based on (manual) user feedback. The scores predicted by this model are used as rewards for the RL agent. Proximal Policy Optimization is then used as a final step to further tune ChatGPT.
In short, retraining or adding new information to LLMs is not fully automated. RL based training remains a complex task and manual intervention is still needed to perform this in a targeted fashion and protect against bias / manipulation.
Personalized LLMs
In this section, we show how the LLM generated responses can be personalized taking into account user sentiment and preferences.
The user sentiment can be computed based on both (explicit) user feedback, expressions, as well as (implicit) environmental aspects, e.g. location (home, office, market, …), temperature, lighting, time of the day, weather, other family members present in the vicinity, and so on; to further adapt the generated response.
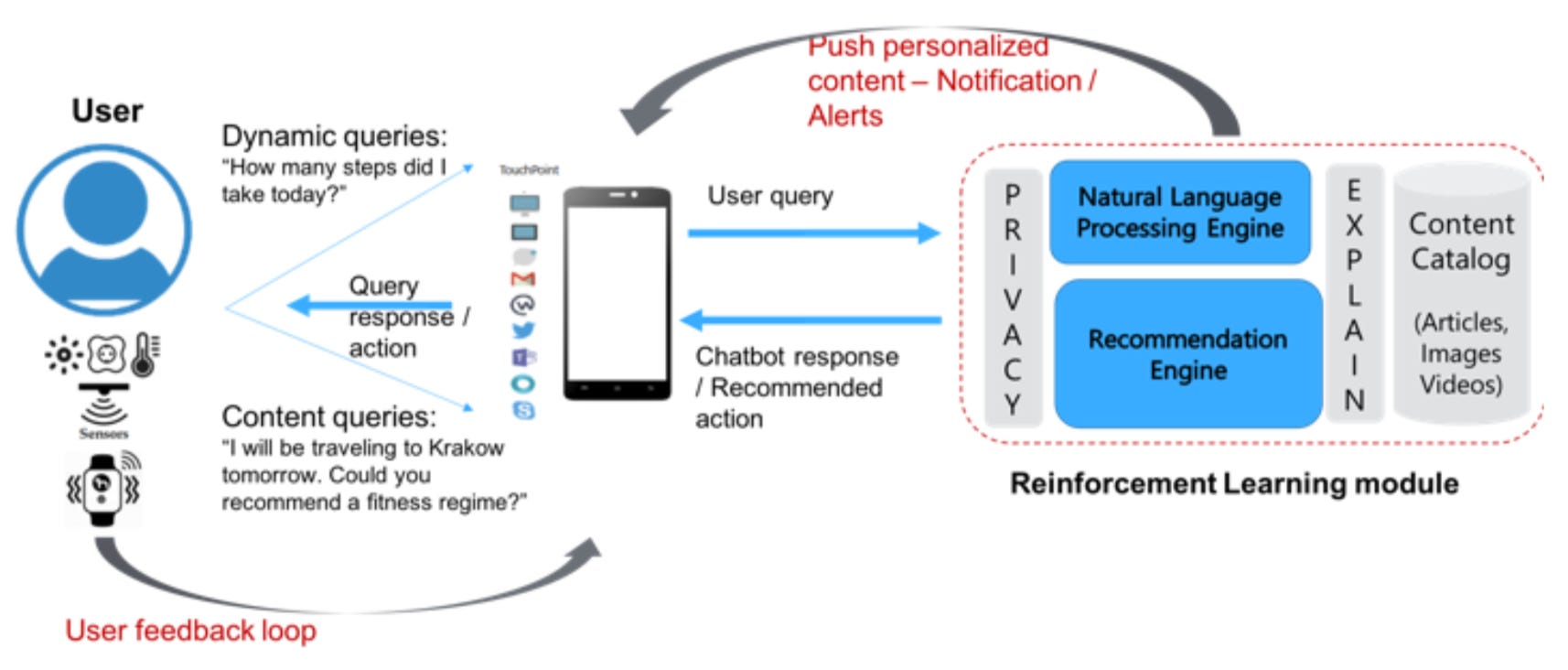
We outline the high level steps below to enable a Reinforcement Learning based Recommendation Engine to personalize the LLM generated responses.
1. The user and environmental conditions are gathered using available sensors to compute the ‘current’ feedback, including environmental context (e.g. webcam pic of the user can be used to infer the user sentiment to a chatbot response / notification, the room lighting conditions and other user present in the vicinity),
2. which is then combined with the user conversation history to quantify the user sentiment curve and discount any sudden changes in sentiment due to unrelated factors;
3. leading to the aggregate reward value corresponding to the last response / app notification provided to the user.
4. This reward value is then provided as feedback to the RL agent, to choose the next optimal LLM generated response / app notification to be provided to the user.
Keep reading with a 7-day free trial
Subscribe to Debmalya’s Substack to keep reading this post and get 7 days of free access to the full post archives.